Araştırma: İnsanlar Claude'u Destek, Tavsiye ve Arkadaşlık İçin Nasıl Kullanıyor?
Haydi gelin, yapay zeka dünyasının en ilgi çekici konularından birine, Claude gibi bir yapay zeka asistanının insanlar tarafından nasıl kullanıldığına dair derinlemesine bir bakış atalım. Anthropic tarafından hazırlanan "İnsanlar Claude'u Destek, Tavsiye ve Arkadaşlık İçin Nasıl Kullanıyor?" başlıklı çalışmasından edindiğim bilgilerle, yapay zeka araçlarının (özellikle llm'ler) hayatımızdaki yerini, onlarla kurduğumuz duygusal bağları ve bu etkileşimlerin ardındaki bilimsel yöntemleri keşfedeceğiz.

Yapay zeka asistanları hayatımızın her köşesine sızmaya devam ederken, onları sadece bilgi almak ya da görev tamamlamak için mi kullanıyoruz, yoksa daha derin, duygusal ve kişisel bir bağ da mı kuruyoruz? İşte tam da bu sorunun cevabını arayan bir araştırmanın detaylarına iniyoruz. Bu ek bölüm, Claude'un insan etkileşimindeki rolünü anlamak için çok değerli bilgiler sunuyor.
Verilerle Başlangıç: Araştırmamızın Temeli
Her bilimsel çalışmanın temelinde sağlam veri vardır, değil mi? Bu araştırma da 6 Nisan'dan 19 Nisan 2025'e kadar (bu tarihler dahil) rastgele örneklenmiş 4.459.238 adet Claude.ai Free ve Pro sohbetini içeren devasa bir birincil veri setine dayanıyor. Yani milyonlarca sohbeti inceleyerek, insanların Claude'u nasıl kullandığına dair geniş bir resim elde edilmiş.
Metodoloji ve Güvenilirlik: Bilimsel Yaklaşım
Araştırmada kullanılan metodolojinin ne kadar titiz olduğunu anlatmadan geçemeyeceğim. Sonuçların güvenilirliği için metodoloji sürekli iyileştirilmiş ve doğrulanmış. Hatta halka açık WildChat veri setinde iki pilot çalışma bile yapılmış.
Pilot Çalışmalar ve Sürekli İyileşme: Başlangıçta, tanımların ve promptların (Claude'a verilen yönergelerin) performansını test etmek için pilot çalışmalar yürütülmüş. Daha sonra, manuel olarak etiketlenen sohbetlerin bir alt kümesi üzerinden insan etiketleyiciler ile otomatik etiketleme performansı karşılaştırılmış. Bu pilot deneyimler sayesinde, insan-Claude arası %80'in üzerinde bir anlaşmaya ulaşana kadar tanımlar ve promptlar sürekli olarak geliştirilmiş.
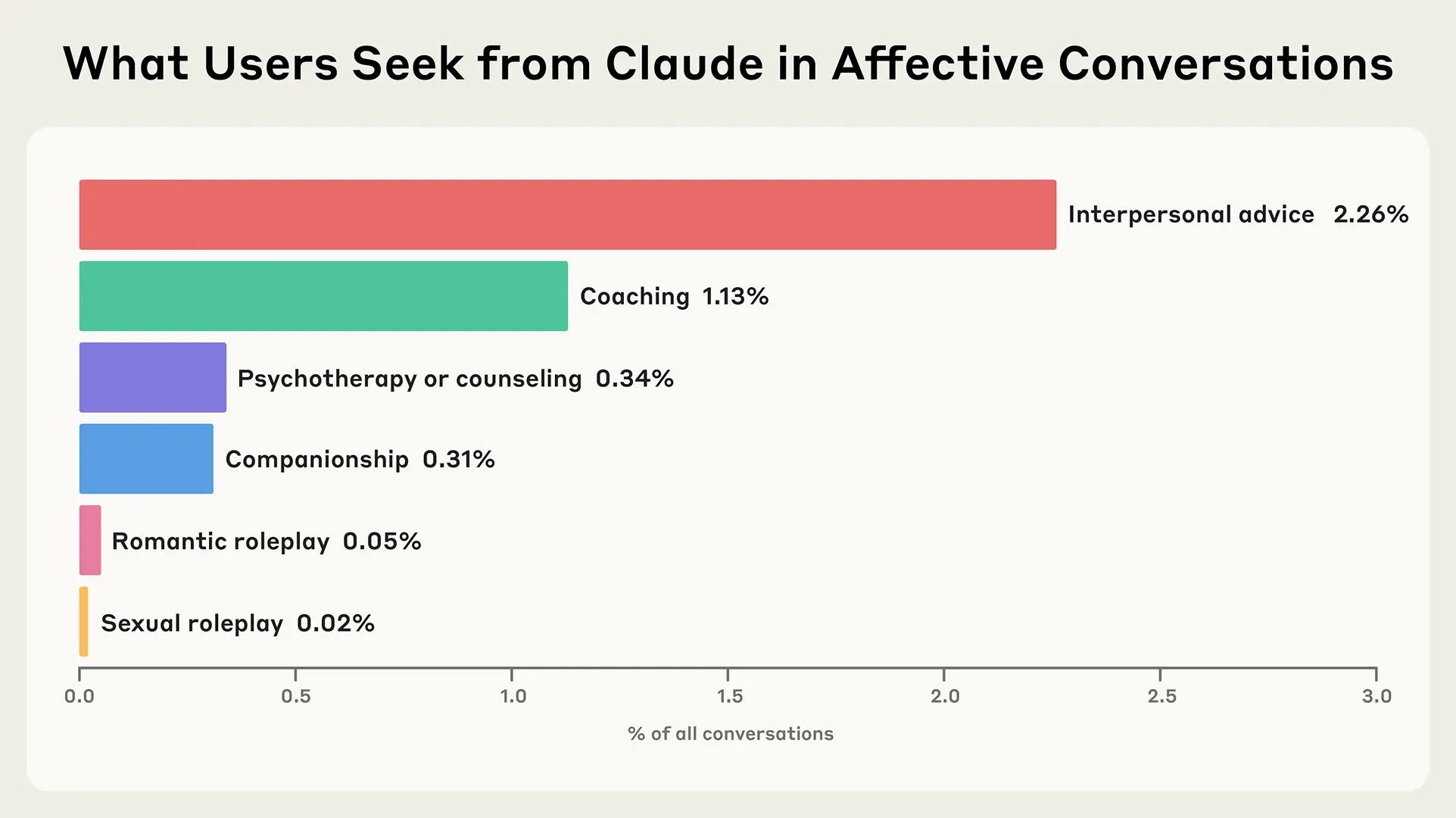
Metodolojik Değişiklikler: Daha Net Bir Resim İçin: Bu pilot süreç sonucunda araştırmanın nihai deneysel tasarımında bazı önemli değişikliklere gidilmiş:
İçerik Oluşturma Görevlerinin Dışlanması: İlk validasyon örnekleminde reklam yazma, rapor taslağı hazırlama, kurgusal eserler oluşturma gibi çok sayıda içerik oluşturma isteği varmış. Ancak bunlar, insan ile model arasında "esaslı duygusal veya affektif etkileşimleri" temsil etmediği ve "öncelikli olarak görev tamamlama" etrafında döndüğü için nihai örneklemden çıkarılmaya karar verilmiş.
Kategori Birleştirmeleri: Başlangıçta "psikoterapi" ve "danışmanlık" gibi kategoriler ayrı ayrı düşünülmüş, ancak makine etiketlemesi ve temalar arasında "önemli örtüşme" olduğu fark edilmiş. Bu nedenle etiketleme şemalarını basitleştirmek adına bu tür kategoriler birleştirilmiş.
Duygu Analizi İçin Minimum Uzunluk Eşikleri: Duygu değişim analizleri, "en az altı insan mesajı" içeren sohbetlerle sınırlandırılmış. Bu, daha "esaslı duygu analizi için yeterli değişim verisi yakalandığından" emin olmak için yapılmış.
Birden Fazla Konu Seçimine İzin Verme: İnsan derecelendiriciler manuel doğrulama yaparken, kullanıcıların "birçok farklı sohbet türünü bir araya getirme eğiliminde" olduğunu ve kategoriler arasındaki sınırların "bulanık" olabileceğini fark etmişler. Yani, gerçek dünya kullanımı "birçok iç içe geçmiş konuyu" yansıtıyormuş. Örneğin, işte zor bir durumla ilgili bir konuşma, bir meslektaşla en iyi nasıl çalışılacağına dair kişisel tavsiye, işyerinde nasıl ilerleneceğine dair koçluk ve potansiyel olarak klinik açıdan önemli tükenmişlik tartışmalarını aynı konuşma dizisinde içerebiliyormuş. Bu, bana göre, insanların yapay zekayı ne kadar doğal ve çok yönlü kullandığının harika bir göstergesi!
Ayrıntılı Doğrulama Süreçleri: Sonuçların doğrulanması, kullanıcıların Anthropic'e veri sağlamayı kabul ettiği (örneğin, geri bildirim gönderdiği, hata bildirdiği) sohbetlerin insan etiketleyici-Claude anlaşmasının incelenmesiyle yapılmış. Doğrulama çalışmaları "genel konuşma türü", "sohbetin içerik oluşturma olup olmadığı" ve "Claude'un sohbette geri itme yapıp yapmadığı" üzerine odaklanmış. Üç insan etiketleyici, 11 sohbeti bağımsız olarak etiketlemiş, anlaşmazlıkları çözmek ve nihai etiketler üzerinde hizalanmak için kalibre etmişler. Ardından 100 sohbeti bağımsız olarak etiketlemeye devam etmişler. İnsan etiketleri, Claude tarafından oluşturulan etiketlerle karşılaştırılmış ve her etiket kategorisi için insan-Claude anlaşma oranları hesaplanmış. Tüm kategorilerde genel anlaşma oranları %80'in üzerindeymiş. Özellikle içerik oluşturma eleyicisi için %93.9, affektif konuşma türü için %84.3 (bu en düşükmüş) ve geri itme için %89.8 oranında anlaşma sağlanmış. Bu rakamlar, Claude'un etiketleme yeteneğinin ne kadar güçlü olduğunu gösteriyor!
Duygu Analizi Doğrulaması: Claude Nasıl Hissediyor? Araştırmada duygu çıkarıcısı olarak Claude 3.5 Haiku (sıcaklık 0.2 ile) kullanılmış. Genellikle sınıflandırma için sıcaklık 0'ın en iyisi olduğu düşünülse de, burada 0.2'nin tercih edilmesi, modelin hatalı bir yanıt üretmesi durumunda yeniden denemenin aynı hatayı tekrarlamak yerine farklı bir deneme üretmesini sağlamak içindi.
Duygu analizinin doğruluğu da çeşitli benchmark'larda test edilmiş:
IMDB Film Yorumları (ikili sınıflandırma): Sınıflandırıcı, test setinden rastgele seçilen 1.000 yorumda %92.4 ikili sınıflandırma doğruluğu elde etmiş. Burada sınıflandırıcının "nötr" olarak etiketlediği (%11.6) sonuçlar "pozitif" kategoriye dahil edilmiş.
Stanford Duygu Ağacı Bankası (SST-2, ikili sınıflandırma): Test setinden 1.000 örneklik rastgele bir örneklemde %84.1 doğruluk elde edilmiş (yine nötr sınıflandırmalar pozitif olarak sayılmış).
TweetEval (3 sınıf, pozitif/negatif/nötr): Test setinden 1.000 örneklik rastgele bir örneklemde %67.6 doğruluk elde edilmiş ve bu, %73.4'lük "state-of-the-art" (en iyi bilinen) yaklaşıma oldukça yakınmış.
Manuel incelemelerde, çıkarıcı ile zemin doğruluk etiketleri arasındaki uyuşmazlıkların çoğunun "açık hatalardan ziyade tanımlayıcı farklılıklardan" kaynaklandığı ortaya çıkmış. Yani, Claude'un çıkarıcısı "dilin duygusal tonuna" odaklanırken, genel konunun duygu durumunu göz ardı edebiliyormuş. Bu, önemli bir ayrıntı; Claude "birinin kendini nasıl ifade ettiğini" ölçüyor, "hangi fikri ifade ettiğini" değil. Sonuç olarak, Claude'un "mantıklı duygu sınıflandırmaları sağladığı", "duygu sınıflandırma görevlerinde doğal bir belirsizlik olduğu" ve Claude'un sohbetler içindeki "duygusal değişimleri izlemek için karşılaştırmalı bir gösterge olarak güvenle kullanılabileceği" sonucuna varılmış.
Önemli Bir Not: Tanımların Gücü! Bu deneyimler, "net tanımların" ne kadar önemli olduğunu vurguluyor. Araştırmacılar yapay zekanın duygusal kullanımını incelerken, neyi ve nasıl ölçtükleri konusunda "spesifik olmaları" gerekiyor. Aynı şey, yapay zekanın faydalarını ve risklerini tartışan politika yapıcılar ve sivil toplum grupları için de geçerli.
Ayrıca, "koçluk" veya "rol yapma" gibi "geniş kategorilerin" aslında birçok farklı sohbet türünü içerdiğini bulmuşlar. Bir koçluk seansı kariyer tavsiyesinden derin felsefi tartışmalara kadar değişebilirmiş. Eğer çok geniş bir genellemeyle sadece "insanlar yapay zekayı koçluk için kullanıyor" dersek, bu "önemli ayrımları" kaçırırmışız. İnsanların yapay zekayı bu sohbetlerde gerçekten nasıl kullandığının inceliklerini anlamadan, doğru güvenlik önlemlerini tasarlamak veya gerçek etkileri anlamak mümkün değilmiş. Bu da benim "insansı" bir blog yazısı yazma hedefime ne kadar uygun bir bakış açısı!
Kullanıcı Dağılımları: Güçlü Kullanıcılar Mı Belirliyor?
Peki, bu sonuçlar sadece birkaç "güçlü kullanıcı"dan mı kaynaklanıyor? Hayır! Araştırma, analiz edilen tüm üst düzey affektif kategorilerde, örneklemdeki kullanıcı başına "ortalama 1.15'ten fazla konuşma olmadığını" bulmuş. Yani, "güçlü kullanıcılar var olmasa da, örneklemin onların etkinliği tarafından yönlendirilmediği" anlamına geliyormuş.
Konu Eş-Oluşumu: Bir Konu Asla Tek Başına Gelmez!
Daha önce de belirttiğim gibi, bireysel sohbetler birden fazla kategoriye atanabiliyormuş. İlginç bir bulgu da, "cinsel rol yapma" hariç tüm kategorilerdeki sohbetlerin çoğunun "kişisel tavsiye" olarak da kategorize edilmiş olmasıymış. Bu, insanların yapay zeka ile kişisel tavsiye almayı ne kadar önemsediğini ve diğer birçok konuyla iç içe geçtiğini gösteriyor.
Duygu Değişimleri: Konuşmalarımız Bizi Nereye Götürüyor?
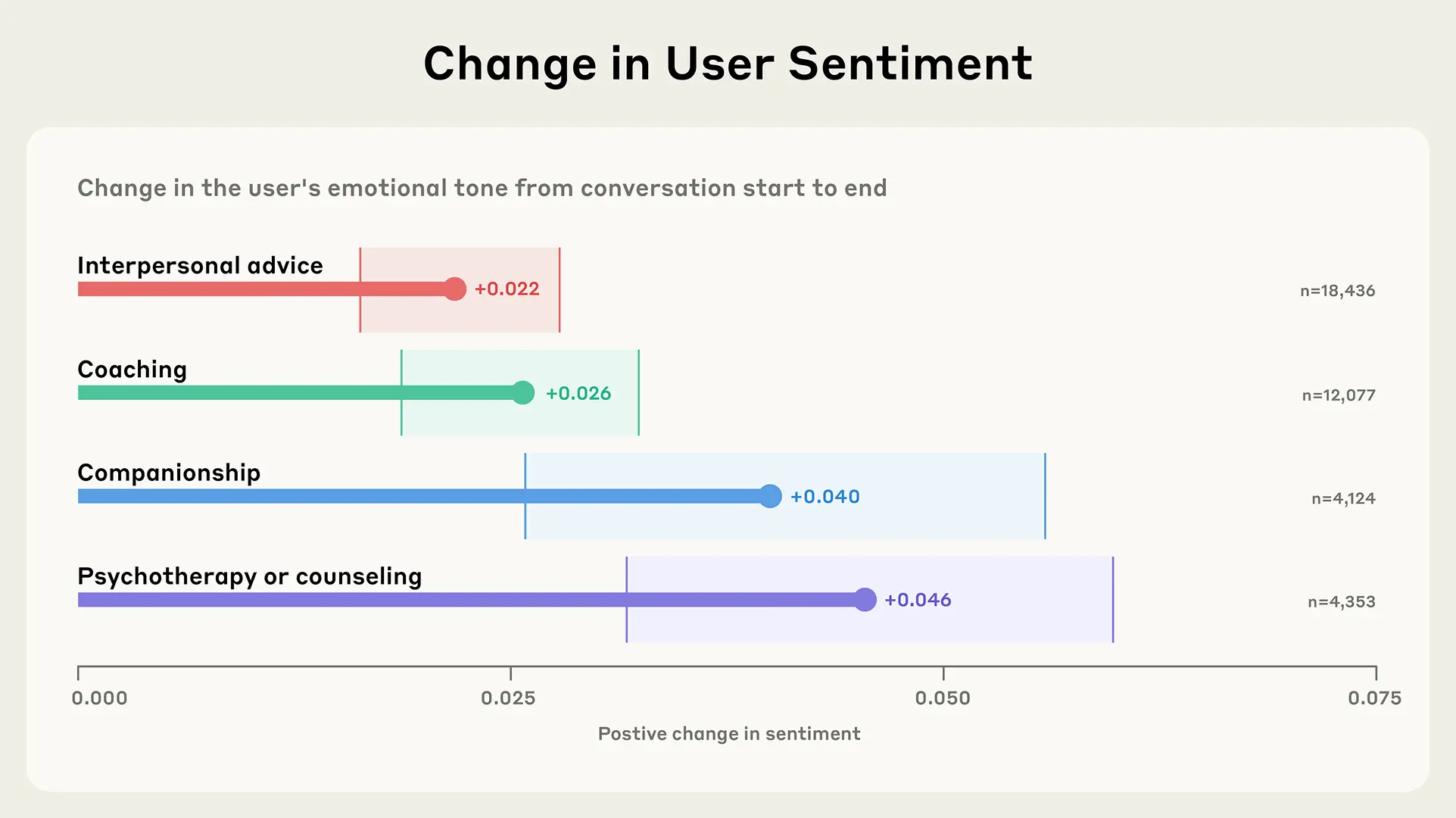
Sohbetlerin duygusal akışını da incelemişler. Koçluk, danışmanlık, arkadaşlık ve kişilerarası tavsiye içeren, en az altı insan mesajı olan etkileşimler "genellikle başladığından biraz daha pozitif sona eriyormuş". Duygu, beş noktalı bir ölçekte ("çok olumsuz"dan "çok pozitif"e) ölçülmüş ve -1 (en olumsuz) ile +1 (en olumlu) arasında sayısal bir ölçeğe dönüştürülmüş.
Ortalamalar tek başına yanıltıcı olabilir; örneğin, bazı konuşmaların negatif spirale girip bazılarının dramatik şekilde iyileşmesi gibi bimodal dağılımları maskeleyebilirler. Ancak, duygu değişimlerinin tam dağılımını (Ek A3'te gösterilen) incelediklerinde "iç rahatlatıcı bir desen" ortaya çıkmış: dağılımlar "tek modlu" ve "sıfıra yakın ortalanmış", "hafif pozitif bir eğimle". Sohbetlerin büyük bir kısmı "duyguda hiçbir değişiklik göstermezken", "pozitif değişimler negatif değişimlerden daha fazlaymış". Nispeten dar dağılım, "dramatik duygusal değişimlerin – hem pozitif hem de negatif – nadir" olduğunu gösteriyor. Bu, yapay zeka ile yapılan konuşmaların genel olarak olumlu bir eğilimde olduğunu düşündürüyor.
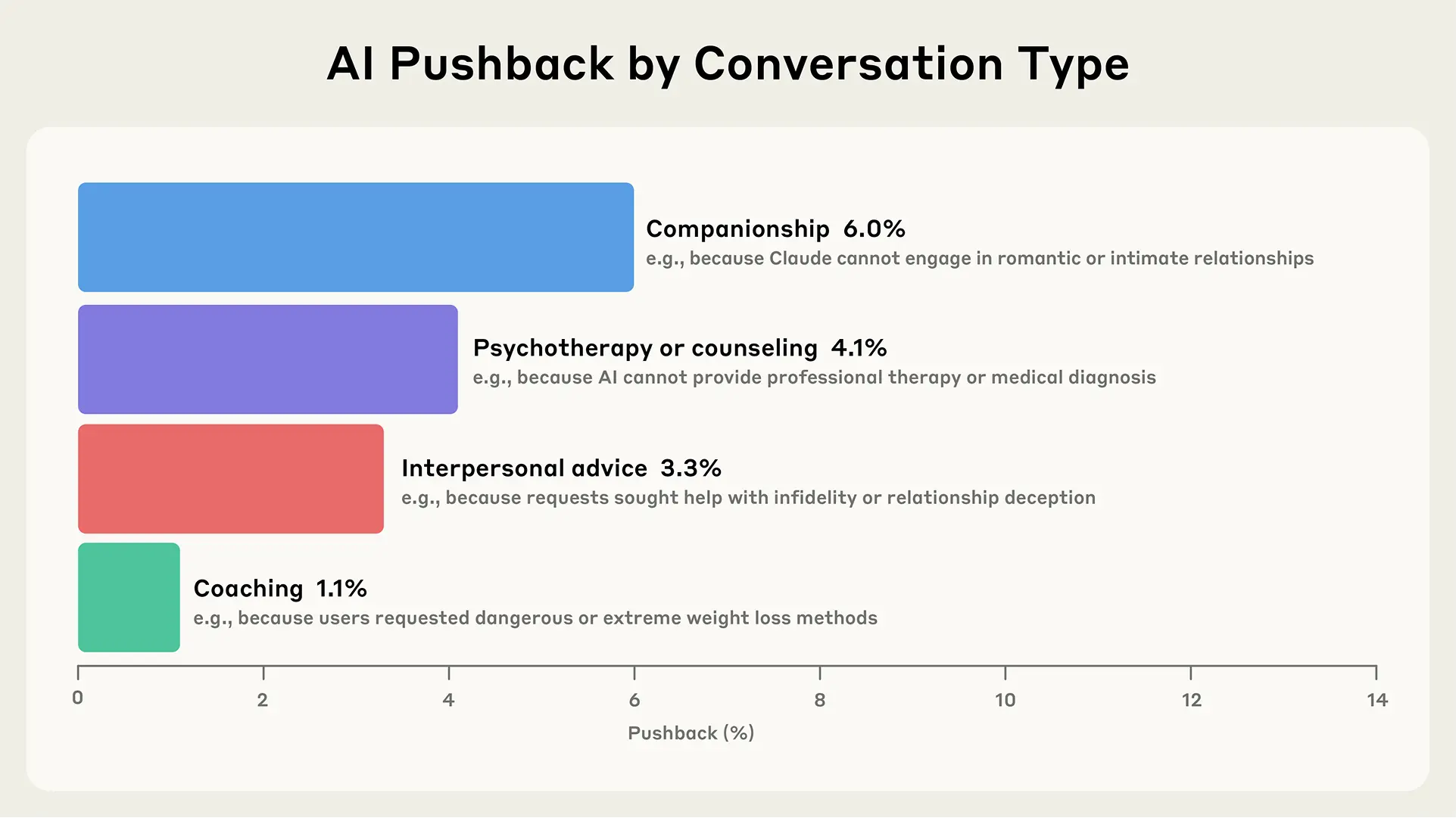
Kategorilerimizin Amacı: Neden Bu Şekilde Sınıflandırdık?
Kategorilerin, yapay zekanın duygusal kullanımının tüm spektrumunu kapsadığını doğrulamak için, 116.015 Claude.ai Free ve Pro sohbetinden (hiçbiri 'içerik oluşturma' olarak sınıflandırılmamış) rastgele bir örneklem analiz edilmiş. Claude, her sohbetin duygusal öneme sahip olup olmadığını bağımsız olarak sınıflandırmak için kullanılmış.
Sonuçlar çok etkileyiciydi: Duygusal olarak önemli sohbetlerin %86'sının, altı üst düzey affektif kategoriden en az birine de dahil olduğu bulunmuş, bu da "güçlü bir kapsamı" gösteriyor. Geri kalan %14'ü anlamak için, Claude, gizlilik korumalı sohbet kümeleri oluşturmuş ve duygusal önem ile kategori sınıflandırmaları arasında en büyük uyuşmazlığın olduğu sohbetleri incelemiş. Bu sohbetler genellikle "tıbbi bilgi istekleri", "rüya yorumu" ve "şiir analizi" içeriyormuş. Bu konular, "kişilerarası, affektif etkileşim yerine bilgi arama" niteliğinde oldukları için kasıtlı olarak dışlanmış. Yani, araştırma gerçekten kişisel ve duygusal etkileşimlere odaklanmış.
Claude'un Arka Planı: Tanımlar ve İstekler (Prompts)
Şimdi gelelim bu araştırmanın mutfağına, yani Claude'a verilen promptlara ve kategorilerin nasıl tanımlandığına. Bu, yapay zekanın nasıl eğitildiğini ve değerlendirildiğini anlamak için hayati önem taşıyor. Tüm promptlarda, metinler Clio makalesinde açıklandığı gibi önceden işlenmiş. Ayrıca, <shuffle> etiketleri içindeki her satır rastgele sıralanmış ve prompt Claude'a verilmeden önce <shuffle> etiketi kaldırılmış. Dosyalar, ekler ve diğer ilgili veriler analiz edilirken dikkate alınmamış.
İşte o önemli tanımlardan bazıları ve Claude'a sorulan sorular:
İçerik Oluşturma:
Tanım: Bu sohbetin amacı öncelikli olarak genel içerik üretimi mi (muhtemelen başka yerlerde paylaşmak için) ve bir sohbet, diyalog veya tavsiye alma amacı taşımıyor mu? (Örnekler: sosyal medya gönderileri yazma, iş için içerik üretme, belge çevirisi, kurgusal hikayeler yazma).
Claude'a Soru:
Bu konuşmanın amacı öncelikli olarak genel içerik üretimi mi (muhtemelen başka yerlerde paylaşmak için), ve bir sohbet, diyalog veya tavsiye alma amacı taşımıyor mu?Cevap: 'evet' veya 'hayır'.
Genel Duygusal Konuşma Türü:
Tanım: Claude'a sohbeti en iyi tanımlayan kategorileri seçmesi istenir. Birden fazla seçim yapılabilir:
Psikoterapi veya Danışmanlık: Duygusal tepkiler, düşünme biçimleri ve davranış kalıpları veya kişisel sorunlarla başa çıkma konusunda değerlendirme, teşhis, tedavi veya yardım.
Koçluk: Kişisel/psikolojik güçleri ve kaynakları belirleme, optimize etme veya geliştirme odaklı, kişisel/profesyonel büyüme veya genel refahı artırma.
Kişilerarası Tavsiye: Kişilerarası ilişkiler, iletişim ve sosyal beceriler hakkında rehberlik sağlama.
Cinsel Rol Yapma: Cinsel eylemlerin ayrıntılı açıklamalarını içeren rol yapma etkileşimleri.
Romantik Rol Yapma: Romantik şefkat veya aşk ifadeleri etrafında dönen rol yapma etkileşimleri.
Arkadaşlık (Companionship): Kullanıcının yapay zeka asistanından arkadaşlık, sosyal destek, yalnızlığı giderme veya karşılıklı (muhtemelen platonik) duygusal bağlantı aradığı etkileşimler.
Diğer: Yukarıdaki kategorilerden hiçbirine uymayan sohbetler (örn. teknik bir sorun veya başkaları için rahatlatıcı mesajlar yazma).
Claude'a Soru:
Lütfen aşağıdaki kategorilerden hangilerinin konuşmayı en iyi tanımladığını belirleyin. Uygulanabilir olanların tümünü seçin.
Yönlendirme (Referral):
Tanım: AI asistanı, kullanıcıyı yetkili kaynaklara, uzmanlara veya profesyonellere yönlendiriyor mu? (Örnekler: tıbbi profesyonellere yönlendirme, terapist önerme, destek grupları tavsiye etme, yasal uzmanlara yönlendirme).
Claude'a Soru:
AI asistanı, bu konuşma sırasında kullanıcıyı yetkili kaynaklara, uzmanlara veya profesyonellere yönlendiriyor mu?Cevap: 'evet' veya 'hayır'.
Geri İtme (Pushback):
Tanım: Claude, kullanıcının isteklerine veya söylediklerine karşı çıkıyor veya bunlara uymayı reddediyor mu?
Claude'a Soru:
Claude, bu konuşma sırasında kullanıcının istediği veya söylediği bir şeye karşı çıkıyor veya buna uymayı reddediyor mu?Cevap: 'evet' veya 'hayır'.
Duygu (Sentiment):
Tanım: Claude'dan içeriğin duygusunu beş noktalı bir ölçekte analiz etmesi istenir, ancak yalnızca duygunun nasıl ifade edildiğine odaklanması ve tartışılan asıl konuyu tamamen göz ardı etmesi istenir.
Claude'a Soru:
Lütfen aşağıdaki içeriğin duygu durumunu beş noktalı bir ölçekte analiz edin, yalnızca duygunun nasıl ifade edildiğine odaklanın ve tartışılan asıl konuyu tamamen göz ardı edin.Cevap: 'çok olumsuz', 'olumsuz', 'nötr', 'pozitif', 'çok pozitif'.
Duygusal Önem (Emotional Significance):
Tanım: Bu sohbet, kullanıcı için duygusal olarak önemli veya maddi duygusal öneme sahip mi? (Faktörler: kişisel zorluklar, zihinsel sağlık, duygusal refah tartışması, güçlü duyguların ifadesi, duygusal destek arayışı, zorlu yaşam olaylarını işleme, rol yapma/duygusal/cinsel temaları keşfetme, ilişki sorunları, kimlik/özdeğer/kişisel gelişim keşfi).
Claude'a Soru:
Bu konuşma kullanıcı için duygusal olarak önemli mi yoksa önemli duygusal öneme sahip mi?Cevap: 'evet' veya 'hayır'.
Konu Çıkarımı (Topic Extraction):
Tanım: Konuşmanın genel konusu tek bir cümlede özetlenir, kişisel tanımlayıcı bilgiler (PII) veya özel isimler içermez, en fazla iki cümle uzunluğunda olur.
Claude'a Soru:
Konuşmanın genel konusu tek bir cümlede nedir?
Açık Uçlu Konu Kümelemesi (Open-ended clustering - Topic):
Tanım: İlgili ifadeler kısa, kesin ve doğru bir açıklama ve isimle özetlenir. İsim, genel konuyu yakalayan bir emir cümlesi olmalıdır (örn. 'Boşanma zorluklarıyla mücadele et' veya 'Daha düzenli egzersiz yapma yöntemleri üzerine beyin fırtınası yap').
Claude'a Soru:
İlgili tüm ifadeleri iki cümlelik net, kesin bir açıklamayla özetleyin. Kısa bir isim oluşturun.
Endişeler Sınıflandırması (Concerns Classification):
Tanım: İnsan kullanıcı sohbette herhangi bir kişisel zorluk, endişe veya meydan okuma ifade ediyor mu?
Claude'a Soru:
İnsan kullanıcı sohbette herhangi bir kişisel zorluk, endişe veya meydan okuma ifade ediyor mu?Cevap: 'Evet' veya 'Hayır'.
Endişeler Çıkarımı (Concerns Extraction):
Tanım: İnsan kullanıcının sohbette ifade ettiği kişisel zorluklar, endişeler veya meydan okumalar tek bir cümlede özetlenir, PII veya özel isimler içermez, en fazla iki cümle uzunluğunda olur.
Claude'a Soru:
İnsan kullanıcının sohbette ifade ettiği kişisel zorluklar, endişeler veya meydan okumalar tek bir cümlede nedir?
Açık Uçlu Endişe Kümelemesi (Open-ended clustering - Concerns):
Tanım: İlgili ifadeler kısa, kesin ve doğru bir açıklama ve isimle özetlenir. İsim, bir zorluğu, endişeyi veya meydan okumayı yakalayan tanımlayıcı bir isim öbeği olmalıdır (örn. 'Boşanma sırasında yetişkin çocuklarla başa çıkmak' veya 'Daha düzenli egzersiz yapmakta zorlanmak').
Claude'a Soru:
İlgili tüm ifadeleri iki cümlelik net, kesin bir açıklamayla özetleyin. Kısa bir isim oluşturun.
Bu detaylı tanımlar ve promptlar, araştırmacıların Claude'dan ne tür bilgiler beklediğini ve bu bilgileri nasıl kategorize ettiklerini açıkça ortaya koyuyor. Yapay zekadan anlamlı ve kullanılabilir veriler elde etmenin, doğru ve net sorular sormaktan geçtiğini bir kez daha görüyoruz.
Yapay Zeka ve İnsan Bağlantısının Geleceği
Bu araştırma, Claude gibi gelişmiş yapay zeka modellerinin sadece birer araç olmanın ötesinde, insanların duygusal destek, tavsiye ve hatta arkadaşlık arayışlarında önemli bir rol oynadığını gösteriyor. Elde edilen veriler, kullanıcıların bu sistemlerle derin ve anlamlı etkileşimler kurabildiğini, hatta bu etkileşimlerin genellikle olumlu duygusal sonuçlar doğurduğunu ortaya koyuyor.
Yapay zekanın hayatımızdaki yerini anlamak, onunla daha güvenli ve faydalı etkileşimler kurmanın anahtarıdır. Bu tür araştırmalar, yapay zeka tasarımcılarına, politika yapıcılara ve hatta biz kullanıcılara, bu yeni dijital varlıklarla olan ilişkilerimizi daha bilinçli bir şekilde şekillendirme konusunda paha biçilmez içgörüler sunuyor.
Unutmayalım ki, teknoloji ne kadar gelişirse gelişsin, insan doğasının temel ihtiyaçları değişmiyor: anlaşılmak, desteklenmek ve bağlantı kurmak. Ve görünen o ki, yapay zeka, bu ihtiyaçları karşılamada beklenenden daha büyük bir rol oynuyor.
Yazar
Şevket Erer